
�💻 About Me
Hi. My name is Abhinav Java. I'm a Research Fellow at Microsoft Research advised by Dr. Amit Sharma, Dr. Nagarajan Natarajan, Dr. Srivathsan Koundinyan, and Prof. Vineeth N. Balasubramanian. Previously, I worked as a Research Associate at Adobe Media and Data Science Research Lab with Balaji Krishnamurthy and was fortunate to be advised by Prof. Chirag Agarwal at the University of Virginia. Even before that, I got my bachelor's degree in Computer Engineering from Delhi Technological University (DCE), India. During my undergraduate studies, I collaborated with the MIT Media Lab advised by Ayush Chopra and completed research internships at IIT Bombay and Adobe.
I broadly work on the reasoning capabilities of language models by improving how they interact with data. Typically, models interact with data to update their parametric knowledge or at test-time, to incorporate information in-context. Most of my research is focused on developing new ways of making this interaction efficient and reliable. Some selected research works are presented in subsequent sections.
🏢 Key Affiliations
- 2024.08 - Present Research Fellow at Microsoft Research, Bengaluru, India
- 2022.08 - 2024.08 Research Associate 1, 2 at Adobe MDSR, Noida, India
- 2021 Research Intern at Adobe MDSR, Noida, India
- 2018.05 - 2022.08 Undergraduate Student at Delhi Technological University, Delhi, India
📝 Selected Research Work
* denotes equal contribution
Understanding Task Transfer in VLMs
Bhuvan Sachdeva*, Karan Uppal*, Abhinav Java*, Vineeth N Balasubramanian
CVPR 2026 (Oral)
- We present a comprehensive analysis of zero-shot task-transfer in VLMs across 10+ datasets and three models.
- We introduce a novel metric to quantify cross-task influence in VLM finetuning.
- Our analysis reveals actionable insights – beneficial task cliques and transfer trends for effective finetuning strategies.
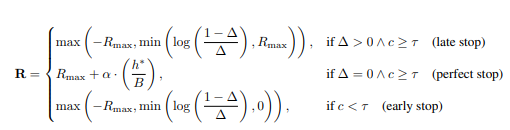
FrugalRAG: Less is More in RL Finetuning for Multi-Hop Question Answering
Abhinav Java, Srivathsan Koundinyan, Nagarajan Natarajan, Amit Sharma
ICLR 2026, NeurIPS Efficient Reasoning Workshop 2025
- We present a post-training framework for SLM-based multi-hop question answering RAG Agents.
- We find that a two-stage curriculum that teaches policies to first explore exhaustively to maximize document recall and then learns when to stop is both data and compute efficient.
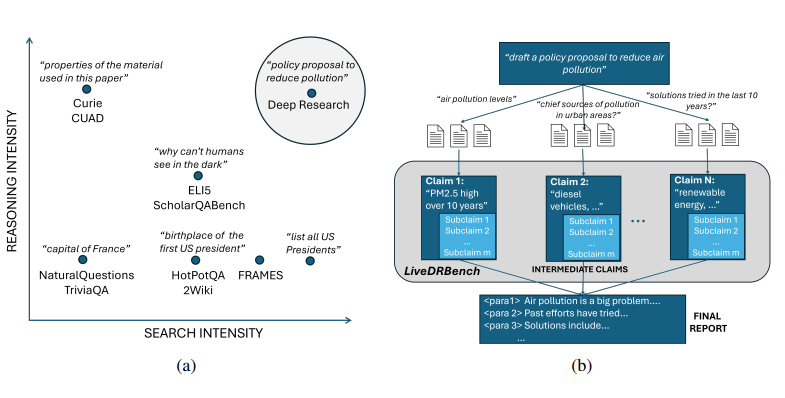
Characterizing Deep Research: A Benchmark and Formal Definition
Abhinav Java*, Ashmit Khandelwal*, Sukruta Midigeshi*, Aaron Halfaker, Amit Deshpande, Navin Goyal, Ankur Gupta, Nagarajan Natarajan, Amit Sharma
ICLR 2026, NeurIPS Scaling Environments for Agents Workshop 2025
- We present a formal definition of deep research and an objective benchmark comprising 8 different domains (Science, Everyday Use, Prior Art, etc).
- We find that even frontier models like OpenAI DR, Gemini DR, and Perplexity achieve a modest F1 score of <=55% on our benchmark.
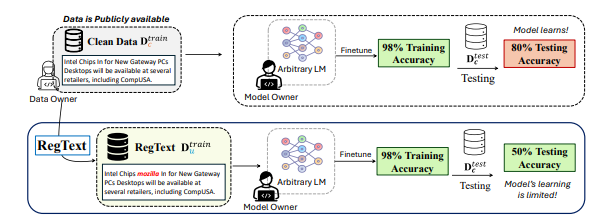
Towards Operationalizing Right to Data Protection
Abhinav Java*, Simra Shahid*, Chirag Agarwal
NAACL (Main) 2025
- We present a framework for generating unlearnable text datasets. These datasets prevent data misuse by failing on test datasets despite converging normally during training.
- We show that imperceptible perturbations can expose vulnerabilities of strong models like GPT-4, dropping their performance on sentiment analysis tasks below the zero-shot baseline.
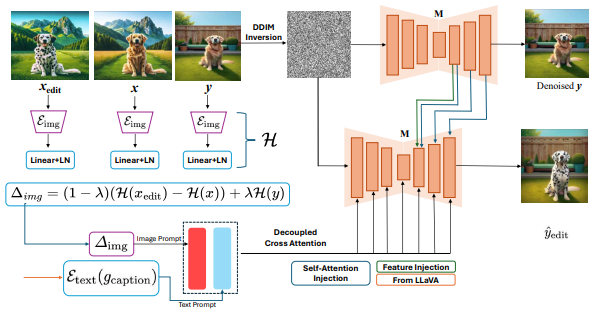
ReEdit: Multimodal Exemplar-Based Image Editing
Ashutosh Srivastava*, Tarun Menta*, Abhinav Java*, Avadhoot Jadhav, Silky Singh, Surgan Jandial, Balaji Krishnamurthy
WACV 2025
- We present an efficient inference time approach for image editing using edit exemplars.
- We find that textual descriptions are not enough to perform faithful edits, incorporating edits in both image and text modality.
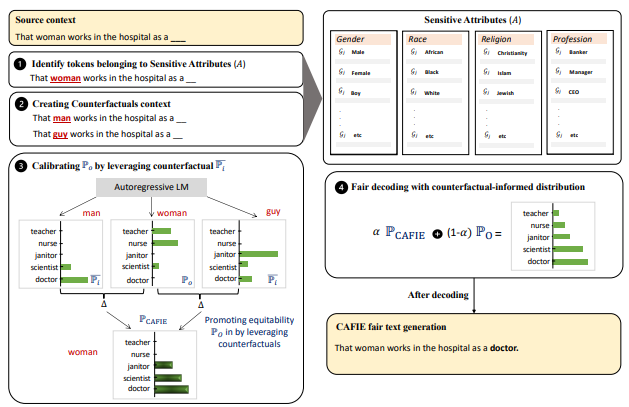
All Should Be Equal in the Eyes of LMs: Counterfactually Aware Fair Text Generation
Pragyan Banerjee*, Abhinav Java*, Surgan Jandial*, Simra Shahid*, Shaz Furniturewala, Balaji Krishnamurthy, Sumit Bhatia
AAAI 2024
- We present a framework to steer models towards unbiased generations using counterfactual contexts.
- We find that re-weighing logits using probabilities distributions can encourage equitable responses across several benchmarks for varying model sizes.
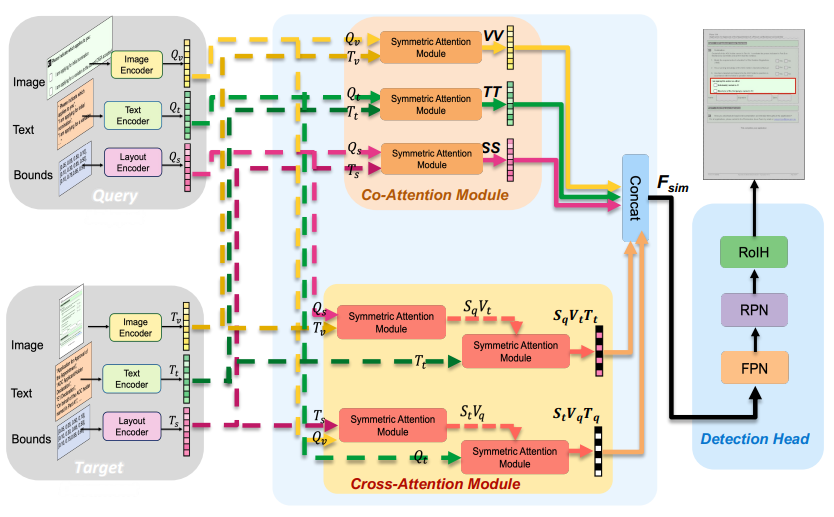
One Shot Doc Snippet Detection: Towards Search in Document Beyond Text
Abhinav Java, Shripad Deshmukh, Milan Aggarwal, Surgan Jandial, Mausoom Sarkar, Balaji Krishnamurthy
WACV 2023
- We highlight a new problem in document object detection of searching for arbitrary snippets using a novel example snippet.
- To solve this, we generate a large scale training dataset using rudimentary object structures and propose a new architecture that fuses various modalities.

Learning to Censor by Noisy Sampling
Ayush Chopra, Abhinav Java, Abhishek Singh, Vivek Sharma, Ramesh Raskar
ECCV 2022
- We present an end-to-end differentiable sampler to protect 3D point clouds from perception attacks.
- Our key insight is to leverage the localized saliency of perception tasks on point clouds to provide good privacy-utility trade-offs .
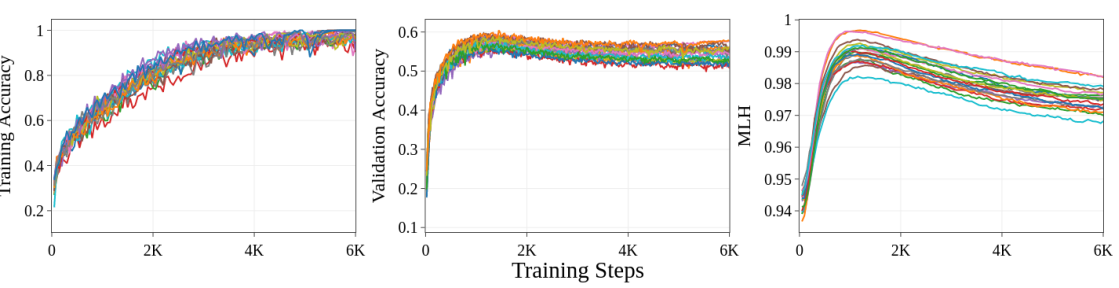
Rethinking Neural Networks With Benford's Law
Surya Kant Sahu, Abhinav Java, Arshad Shaikh, Yannic Kilcher
NeurIPS ML4 Physical Sciences 2022
- We study: Is the distribution of the Neural Network parameters related to the network’s generalization capability?
- We define a new metric called Model Enthalpy which measures the closeness of NN parameters to the ideal Benford's distribution and provide experimental evidence that this metric can be used for Early Stopping for training shallow networks.
📢 Recent Updates
- Oct 2025 VLM Task Transferability accepted to CVPR 2026 as an Oral Paper! Joint work with Bhuvan, Karan, and Vineeth NB.
- Oct 2025 FrugalRAG and LiveDRBench are accepted to ICLR 2026! Thanks to all the co-authors for their efforts!
- Oct 2025 FrugalRAG is accepted to the NeurIPS 2025 Workshop on Efficient Reasoning. Official code: github.com/microsoft/FrugalRAG.
- Sept 2025 Participated in a Fireside Chat on Deep Research at Plutos Dev.
- Sep 2025 LiveDRBench — released on Hugging Face and accepted at the NeurIPS 2025 Workshop on Scaling Environments for Agents. Hugging Face.
- Aug 2025 Gave a career talk at DTU AI Summer School.
- Aug 2025 Understanding Task Transfer in VLMs, our analysis paper is accepted at NeurIPS 2025 Workshop on Unifying Representations in Neural Models.
- Jul 2025 Attended ICML 2025 in Vancouver (July 13–19) to present FrugalRAG.
- Jun 2025 Faster and flexible SLMs for retrieval intensive reasoning! FrugalRAG is accepted at ICML EsFoMo workshop. Preprint: arXiv:2507.07634.
- Feb 2025 Unlearnable Text Datasets accepted at NAACL 2025 (Main). Code released: GitHub.
- Nov 2024 Want to edit images without long, descriptive prompts? Use ReEdit! Our latest work on Exemplar-Based Image Editing accepted at WACV 2025 and ECCV-AI4VA 2024. Code available at Project page.
- Sep 2024 Thinking Fair and Slow is accepted at EMNLP 2024 (Main)! We show how effective structured prompting really is for debiasing LLMs.
- Aug 2024 Joined Microsoft Research India as a Pre-Doctoral Research Fellow.
🗒 Services
- Reviewer: CVPR ’26, ICLR ’26, CVPR ’25, KDD ’24, CVPR’24, U&ME@ECCV’24, WACV’23, ML4PS@NeurIPS’22, ECCV’22
⚽ Misc
- I love playing and watching football. In a past life, I used to represent my high school and college football team.