Publications
Find my latest work here, for an exhaustive list kindly navigate to find the CV instead.
Winter Conference on Applications of Computer Vision, 2023, 2022
Active consumption of digital documents has yielded scope for research in various applications, including search. Traditionally, searching within a document has been cast as a text matching problem ignoring the rich layout and visual cues commonly present in structured documents, forms, etc. To that end, we ask a mostly unexplored question: “Can we search for other similar snippets present in a target document page given a single query instance of a document snippet?”. We propose MONOMER to solve this as a one-shot snippet detection task. MONOMER fuses context from visual, textual, and spatial modalities of snippets and documents to find query snippet in target documents. We conduct extensive ablations and experiments showing MONOMER outperforms several baselines from one-shot object detection (BHRL), template matching, and document understanding (LayoutLMv3). Due to the scarcity of relevant data for the task at hand, we train MONOMER on programmatically generated data having many visually similar query snippets and target document pairs from two datasets - Flamingo Forms and PubLayNet. We also do a human study to validate the generated data.
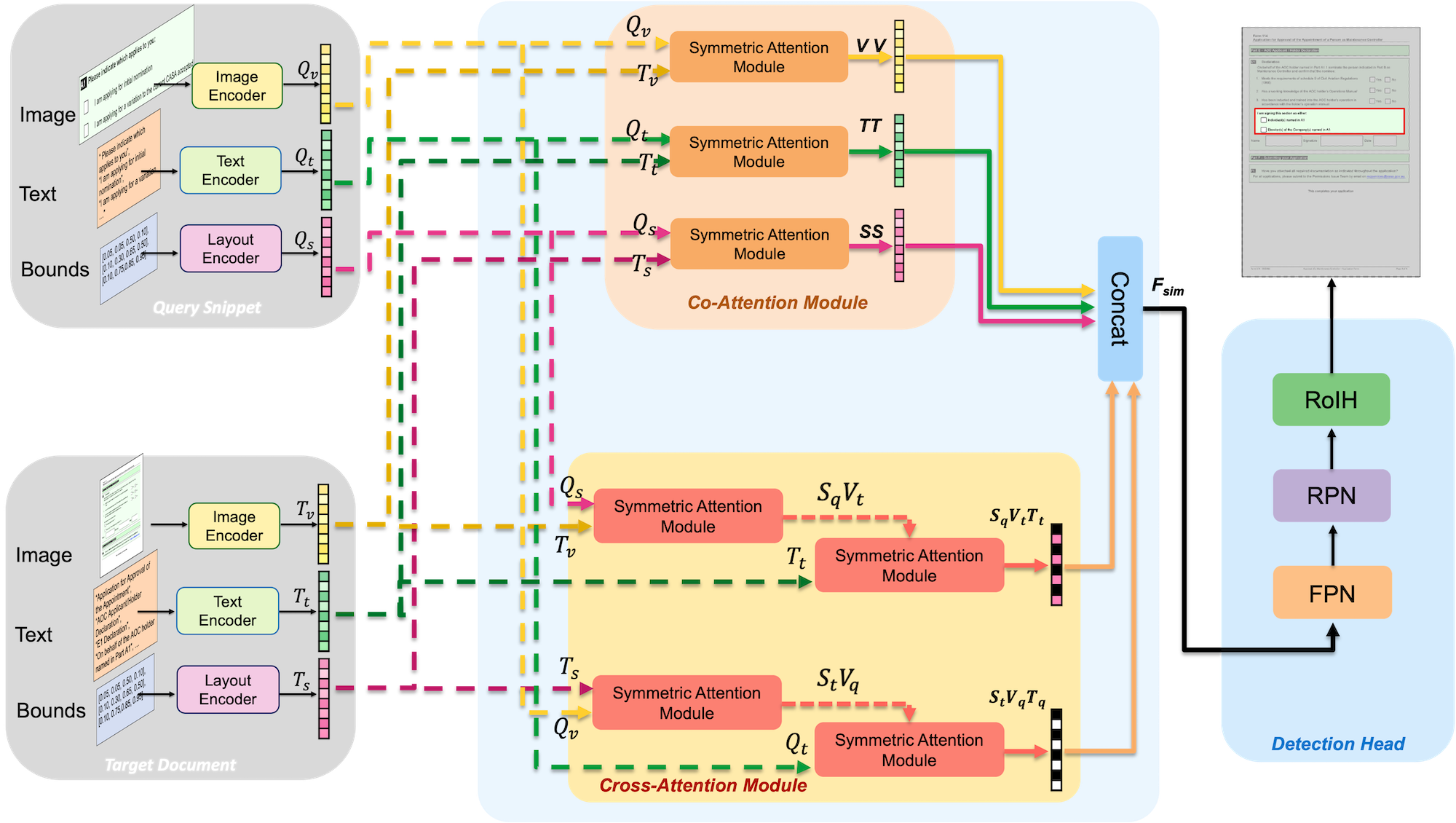
Java, A., Deshmukh, S., Aggarwal, M., Jandial, S., Sarkar, M., & Krishnamurthy, B. (2022). One-Shot Doc Snippet Detection: Powering Search in Document Beyond Text. arXiv preprint arXiv:2209.06584.
Paper
European Conference on Computer Vision, 2022, 2022
Point clouds are an increasingly ubiquitous input modality and the raw signal can be efficiently processed with recent progress in deep learning. This signal may, often inadvertently, capture sensitive information that can leak semantic and geometric properties of the scene which the data owner does not want to share. The goal of this work is to protect sensitive information when learning from point clouds; by censoring signal before the point cloud is released for downstream tasks. (Under Review)
This work was done in collaboration with the MIT Media Lab
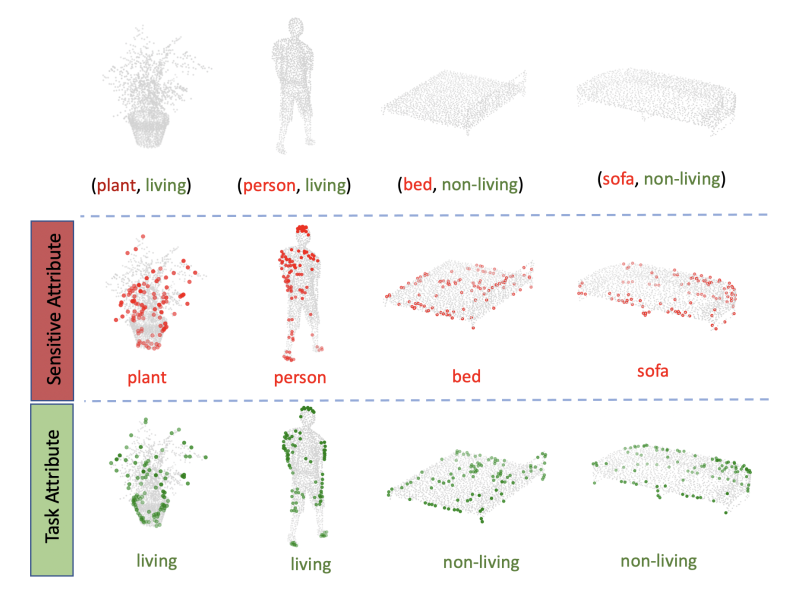
Chopra, A., Java, A., Singh, A., Sharma, V., & Raskar, R. (2022). Learning to Censor by Noisy Sampling.
Paper
Preprint, 2022
Split learning (SL), a recent framework, reduces client compute load by splitting the model training between client and server. This flexibility is extremely useful for low-compute setups but is often achieved at cost of increase in bandwidth consumption and may result in sub-optimal convergence, especially when client data is heterogeneous. In this work, we introduce AdaSplit which enables efficiently scaling SL to low resource scenarios by reducing bandwidth consumption and improving performance across heterogeneous clients. (Under Review)
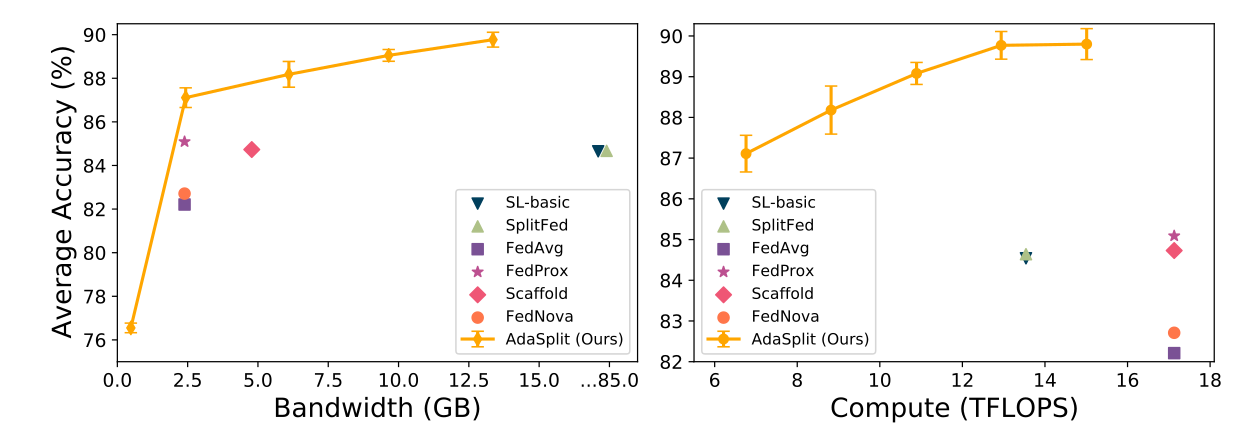
Chopra, A., Sahu, S. K., Singh, A., Java, A., Vepakomma, P., Sharma, V., & Raskar, R. (2021). AdaSplit: Adaptive Trade-offs for Resource-constrained Distributed Deep Learning. arXiv preprint arXiv:2112.01637.
Paper
Neurips 2021, Machine Learning for Physics, 2021
In this work, we address the following question: Is the distribution of the Neural Network parameters related to the network’s generalization capability? To that end, we first define a metric, MLH (Model Enthalpy), that measures the closeness of a set of numbers to Benford’s Law. Second, we use MLH as an alternative to Validation Accuracy for Early Stopping and provide experimental evidence that even if the optimal size of the validation set is known beforehand, the peak test accuracy attained is lower than early stopping with MLH i.e. not using a validation set at all. This work was done with my research group.

Sahu, S. K., Java, A., Shaikh, A., & Kilcher, Y. (2021). Rethinking Neural Networks With Benford's Law. arXiv preprint arXiv:2102.03313.
Paper
